![]()
Image classification and Object detection are some of the most researched areas in computer vision and image processing. Some people often confuses between image classification and object detection. Image classification is used to identify the category of the image whereas the object detection is used to detect different objects present in an image. It works with finding the location of different objects in an image.
One of the most important characteristic of object detection using deep learning is availability of dataset. Larger dataset helps in finding more patterns and delivering better accuracy. Today image processing is used in many fields such as counting the vehicle plates or counting number of vehicles passing. Object detection is accomplished using following steps.


Step 1: Calculate the bounding box using model or algorithm. Such a region of interest is also called Region Proposal (RP).
Step 2: Calculate the features inside each box. For overlapping boxes, transform them into single block
Step 3: Pass these to the deep learning model such as VGG-16 to predict the output using the softmax layer.
Region of interest or bounding box can be calculated using Clustering approach where boxes are formed based on pixels similarities. Features of the objects contained in the bounding box can be calculated using one of these approaches such as Deep learning mode, Histogram approach or passing it through any pre-trained model.
Let us discuss Different deep learning architecture for performing object detection on real time objects.
Single Shot Multi-Box Detector:
Single Shot Multi-Box Detector is one of the architecture for implementing object detection. It discretizes the output space of bounding boxes into a set of default boxes over different aspect ratios and scales per feature map location. Please refer to the following steps to know the working of SSMD Model.
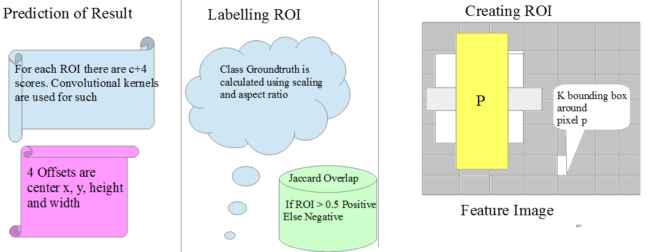
- Creating the ROI: Region of interest is created around the pixel in the feature map. Bounding Box of different aspect ratio is made. Please refer to the above image to understand my point of presentation.
- Labelling ROI: Groundtruth is calculated using scaling and aspect ratio. Jaccard Overlap is applied which states that if ROI is greater than 0.5 such ROI is treated as positive else negative.
- Predicting the Result: For each ROI, there are c+4 scores. Convolution Kernels are used for such. 4 offsets are center x, center y, height and width.
Faster R-CNN: This is another deep learning architecture which makes use of some deep learning pre-trained models such as VGG-16, ZFnet (Advanced version of AlexNet) for creating the feature map. It contains two parts which are as below
- Region Proposal Network
- Detector
Region Proposal Network: This is used for creating the bounding box or region of interest. Input image is feeded to either VGG-16 or ZFnet (Advanced version of AlexNet).
- VGG-16: It contains Convolutional Layer + ReLU , max pool, Fully Connected + ReLU and Softmax.
- ZFnet: It conatins 5 convolutional Layers and 3 Fully connected layers.
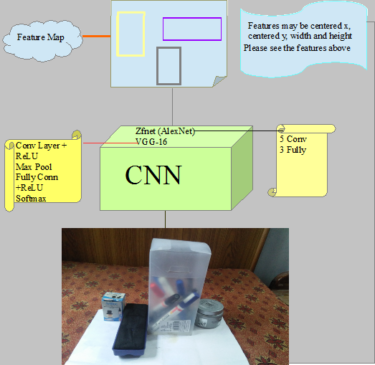
When image contains the intersection of Ground-truth boxes and anchor boxes (IoU) which is passed through either VGG-16 or ZFnet Pretrained network. It is different from its previous versions as it selective clustering algorithm is not run on the input image which makes its speed high while keeping the accuracy high. Output of the model contains features such as center x, center y, height and width along with the finding the presence of object in a particular bounding box. Please refer the image with caption Region of Proposal Faster R-CNN for understanding my point of view.
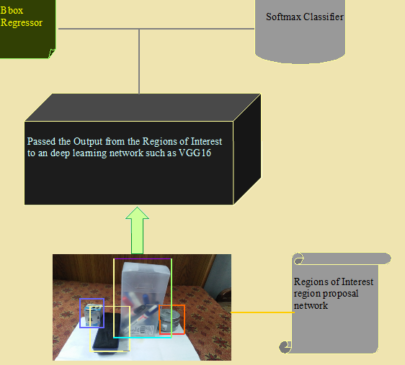
Detector: At the detection part, Image formed with ROI is passed to some pretrained network such as VGG16 which results in two outputs [output1: Softmax Classifier] and [output 2: Bbox Regressor]. Please look at the image with caption Faster R-CNN detector.
Please spend some time for completing AI Sangam Survey. It will help you if you have vision of programming in your mind.
Conclusion: At the end, it can be concluded that as deep learning is making progression day by day, new designs and approaches are coming as a result. We can look at the Faster R-CNN which has eliminated the need of Selective clustering approach. Also use of pre-trained models in such architectures saves a lot of time. VGG-16 is used with these models to form the feature maps and convolution kernels in the detection part to predict the score. Hope you like the post. We have also worked on Real time Face Detection on custom images using Tensor-flow Deep learning model. Please click on the above link to view video. Please visit our official site www.aisangam.com for looking at all the services provided by us. You can also email us your query at aisangamofficial@gmail.com. Thank you for sparing some time to read this post. Please subscribe AI Sangam you tube channel for more updates and videos.