![]()
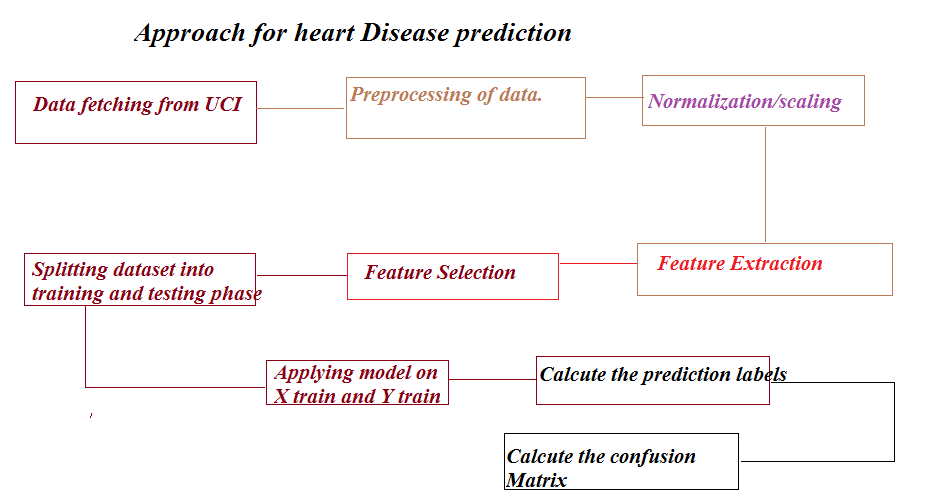
This article applies heart disease prediction having multiclass values in the target column using machine learning and python environment. Dataset is taken from UCI Machine learning repository. Please click on this link to download the heart dataset (new.data). Sample contains 18492 rows and 8 columns. Data contains many string, missing and NaN values. Data is read using pandas and every operation is performed using jupyter notebook. At the end DecisionTreeClassifier is applied to do prediction. There are many steps followed in the way which are essential for better learning. Please refer to the following figure 1 to know these steps.
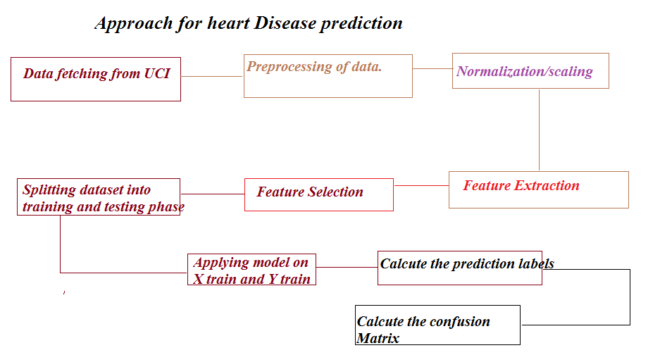
Step1: Data downloaded from UCI repository is read using pandas. We are showing our approach. You may use anything else as you wish.
Step2: Missing values, string values and NaN values are removed using appropriate algorithm.
Step3: Normalization: This step is important when the data in the columns having many values which are very far from each other so it is difficult for machine to understand those values. So data except target is bounded to interval [0 1] so that machine can understand the data in better way.
Step4: Feature Extraction using PCA: PCA provides pair of Eigen values and Eigen vectors. Eigen vector represents direction and values represents the magnitude of variance. This method change the representation into principal components space representation.
Step5: Matrix obtained in the step4 is fed to feature selection algorithm which gives the rank of every column which is compared with the threshold and redundant columns are removed. Basic aim is to remove those variables or columns which have much correlation between them.
Step6: Spliting the data and target into training and testing phase: Once you have done with the above step, it is the time to split the data into training and testing phase. Model is trained with X_train and y_train, whereas the testing is done on the X_test. I represent X as data and y is target. You may your own representation.
Step7: Decision tree classifier is used to train X_train and y_train.
Step8: Model is tested on X_test which gives the labels predicted by machine.
Step9: Predicted labels are tested with y_test to provide the performance evaluation.
Note
X_train: Training data ,Y_train: Training target, X_test: Testing dataset, Y_test: Testing target.


